Selective Quantization for Low General Quality Loss Compression in Language Models
February 2026We are excited to share our latest research on selective quantization techniques designed to minimize general quality loss during model compression for language model transport. This work addresses a critical challenge in deploying large language models: efficiently transferring models while maintaining their performance across diverse tasks.
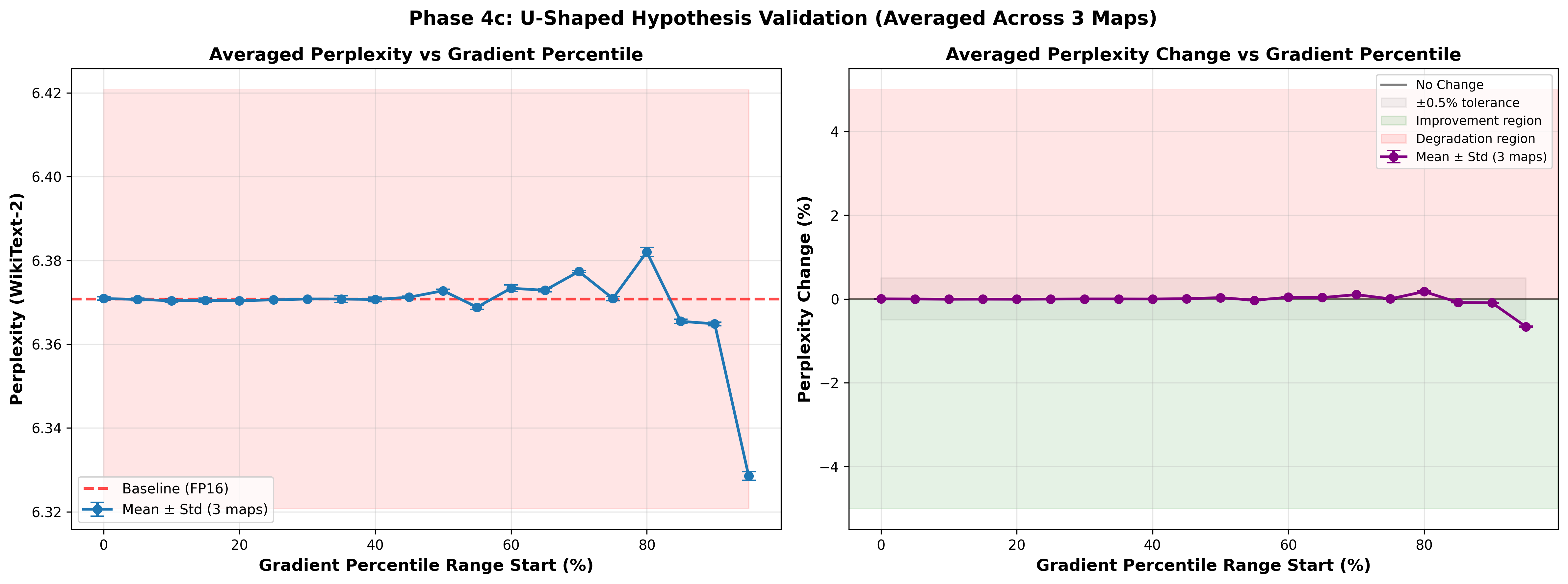
Our selective quantization approach strategically identifies and preserves critical model components during the compression process. The key insight is that near quality loss free compression can be achieved by only compressing the weights that are not susceptible to precision reduction. By selectively protecting sensitive weights while aggressively compressing others, we achieve significantly reduced quality degradation compared to traditional uniform quantization methods.
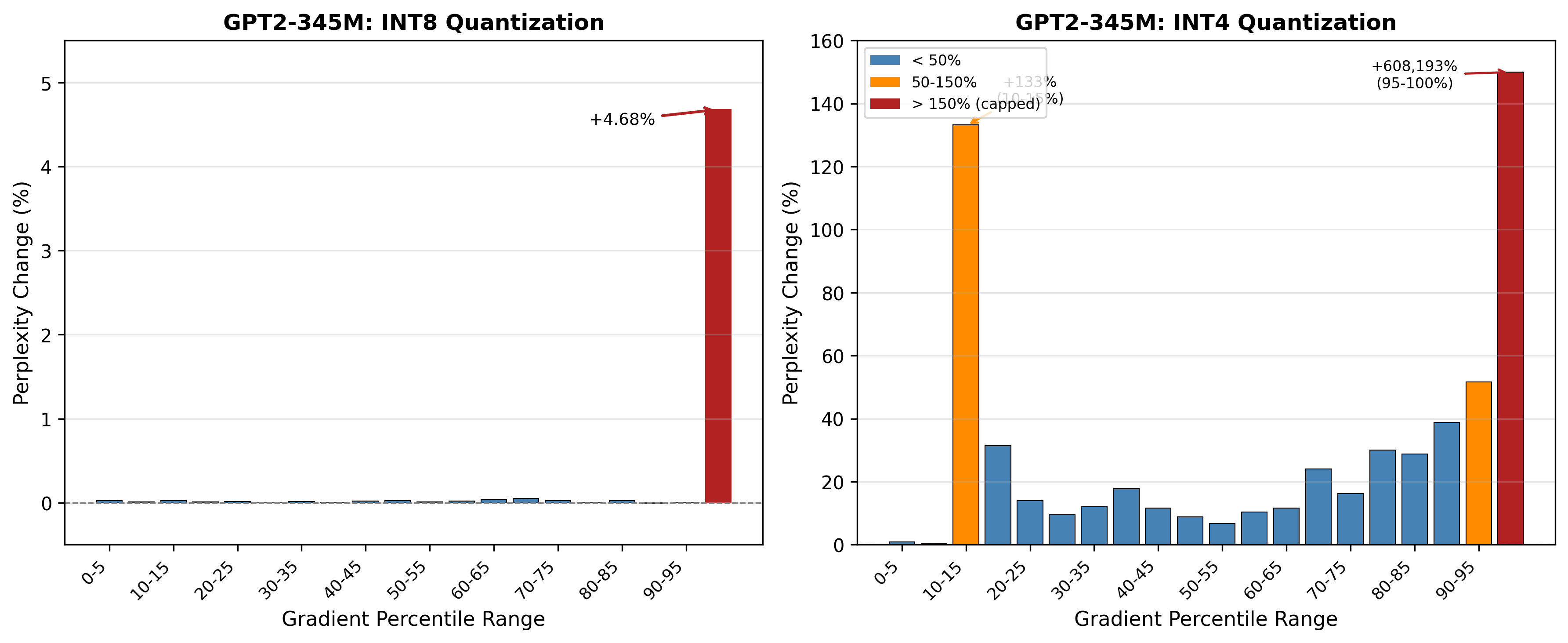
This enables more efficient model distribution and deployment without sacrificing the versatility that makes language models valuable. The technique allows for substantial model size reduction while maintaining performance across diverse tasks.
Publication coming soon. Stay tuned for detailed technical insights and experimental results.